Claude Fable 5 hits a new AI freelance automation record, but human labor remains essential
Published by AINave Editorial • Reviewed by Ramit
Anthropic's Claude Fable 5 has set a new record for AI freelance work automation, achieving a 16.1% automation rate on the CAIS Remote Labor Index (RLI). That is roughly double the 8.3% scored by Opus 4.8 and well above GPT-5.5's 6.3%. But the benchmark also makes clear that full replacement of human freelancers is not imminent, and builders should plan for agent-based workflows with robust human-in-the-loop controls.
What happened
The Center for AI Safety (CAIS) tested Fable 5 on its Remote Labor Index, which measures how often AI agents can complete real, economically valuable freelance projects at a quality a paying client would accept. Tasks included designing a 3D mockup of an engagement ring, creating a video ad, and mapping a floor plan. Each deliverable was evaluated by humans against a professional standard.
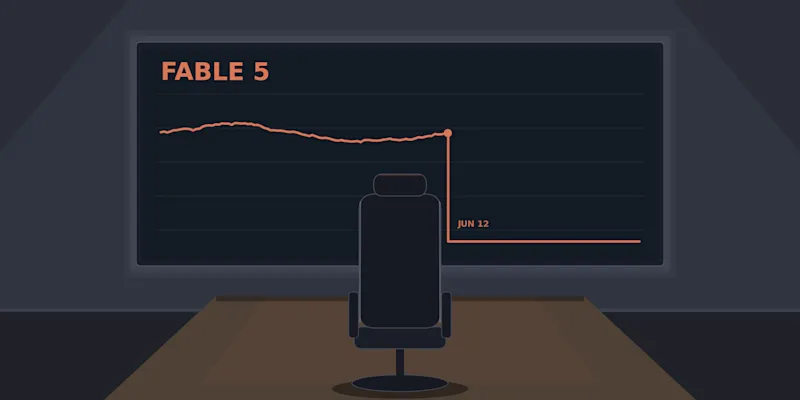
Fable 5 hit 16.1%, a record for the benchmark. For context, the previous leader was Opus 4.6 at 4.17%, and the field topped out at 2.5% when RLI launched. CAIS noted that the frontier has more than quadrupled in under eight months, a concrete signal of how quickly economically capable AI agents are advancing.
The testing was cut short when the US government briefly paused Fable 5 in mid-June. But even under the worst-case assumption that Fable 5 failed every missing project, its automation rate would still be 14.6%, higher than any other model.
Why AI builders should care
For teams building AI products and agent workflows, the RLI results show that the ceiling for autonomous task completion is rising fast. The automation rate quadrupled in eight months, which means the models you evaluate today may look very different in a few quarters.
But the benchmark also reveals where current agents still struggle. CAIS found that tasks quick for a skilled professional, such as transcribing music or playtesting a real-time game, remain out of reach for AI. Meanwhile, work that would take a person hours, such as digital art or coding, is finished by current models in minutes. This uneven progress means builders cannot assume a linear relationship between task duration and AI capability.
Practical implications
To fully replace human freelancers, organizations would likely need a network of agents to validate work quality, budget, and timelines. The tradeoff is not one-to-one. CAIS also tried to replace the human evaluator with an LLM judge, but the model failed. Evaluating an RLI deliverable requires opening project files in professional applications and forming a judgment the way a client would, the very computer-use skills that today's agents are still weakest at.
For builders, this means that even with a model as capable as Fable 5, production deployments still need human oversight for quality assurance, especially for complex or creative deliverables. The path to full automation will require improvements in computer-use skills, agent orchestration, and governance frameworks.
Caveats
Real-world deployment of Fable 5 remains limited by security concerns, safeguards, and governance requirements. The model was briefly paused by the US government and only re-authorized on June 30. Anthropic has said Fable 5 shares capability similarities with Mythos 5, which remains available only for select organizations. Builders should also note that the RLI results are based on partial testing, and the benchmark measures a specific set of freelance tasks that may not represent all remote work categories.
FAQs
What is Claude Fable 5 and how does it differ from previous Anthropic models?
Claude Fable 5 is a Mythos-class model designed for autonomous multi-step workflows with improved data handling and efficiency, according to Anthropic's release notes. It emphasizes longer autonomous operation and stronger integration across knowledge work, vision, memory, and life sciences compared to earlier models like Opus 4.8.
Can Claude Fable 5 replace human freelancers?
Not yet. The CAIS Remote Labor Index results show a high automation rate for Fable 5 in benchmarks, but CAIS notes that full replacement would require a network of agents and robust human-in-the-loop checks. Security, governance, and adoption barriers also slow real-world deployment.
How does Fable 5's performance compare with Opus 4.8 and GPT-5.5?
In CAIS RLI benchmarking, Fable 5 achieved 16.1%, roughly double Opus 4.8 at 8.3% and higher than GPT-5.5 at 6.3%. Opus 4.6 scored 4.17%, with historical leadership at 2.5% when RLI launched.
What is Mythos 5 and how is it related to Fable 5?
Mythos 5 is another frontier model in Anthropic's lineup. Fable 5 and Mythos 5 share capability classes and are referenced together in statements about autonomous work capabilities. Anthropic's materials describe Mythos as part of the same family with evolving capabilities, though Mythos 5 remains available only for select organizations.
Sources
- Fable 5 just set a new AI freelance work performance record - but it can't replace humans yet
- Claude Fable 5 Is Here: Benchmarks, Real-World Performance ...
- Claude Fable 5 and Claude Mythos 5 \ Anthropic
- Anthropic's New Fable 5 AI Model Can Work For Days—But It Won ...
- Claude Fable \ Anthropic
- Is Anthropic’s Fable 5 Coming Back This Week? (Update: It Has)
- Anthropic sets AI performance records with new Mythos 5, Fable 5 frontier models
- Claude Fable 5: What Anthropic’s New Model Means for Your ...
- FABLE 5: Anthropic’s New $10/Million AI That Crushes... - YouTube
- Fable 5 AI — Independent Model Guide & Prompt Workspace
- Anthropic Redeploys Claude Fable 5 on July 1 After... - MarkTechPost
- Redeploying Claude Fable 5 \ Anthropic
Latest Tech News